Figure 1: A batch of example images of handwritten digits.
Build a model
We start off with building a baseline model that simply takes all individual pixels and passes them through a fully connected network.
Code
class BaselineModel(nn.Module):def__init__(self):super().__init__()self.flatten = nn.Flatten()self.linear1 = nn.Linear(in_features=28*28, out_features=16)self.linear2 = nn.Linear(in_features=16, out_features=10)def forward(self, x): x =self.flatten(x) x = F.relu(self.linear1(x)) x =self.linear2(x)return x
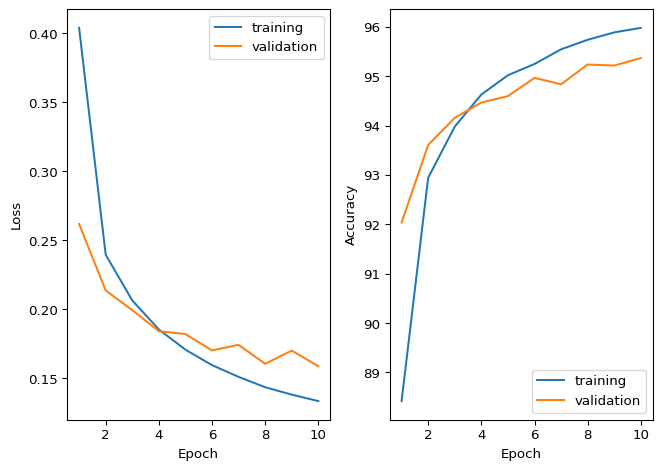
Train the model
In PyTorch we need to make sure that the model and data live on the same device. Obviously, if we can use a GPU to speed up the training, we would do this. Therefore, we first check for the device, and then move the model and data there.
Code
device = torch.device("cuda"if torch.cuda.is_available() else"cpu")# Create an instance of the modelbaseline_model = BaselineModel().to(device)# Define the loss function to useloss_fn = nn.CrossEntropyLoss()# Use a common optimizeroptimizer = optim.Adam(baseline_model.parameters(), lr=0.001)
We define a separate function for validation that we can call after each training epoch:
Code
def eval_step( model: nn.Module, dataloader: DataLoader, loss_fn: nn.Module, device: torch.device):# Put the model in eval mode model.eval()# Initialize performance metrics running_loss =0.0 correct =0 total =0with torch.no_grad():for features, targets in dataloader:# Put the data and target to the device features, targets = features.to(device), targets.to(device)# Make predictions -- forward propagation predictions = model(features)# Calculate the loss loss = loss_fn(predictions, targets)# Track progress running_loss += loss.item() _, predicted = torch.max(predictions, 1) total += targets.size(0) correct += (predicted == targets).sum().item() avg_loss = running_loss /len(dataloader) accuracy =100.* correct / totalreturn avg_loss, accuracydef train_step( model: nn.Module, dataloader: DataLoader, loss_fn: nn.Module, optimizer: optim.Optimizer, device: torch.device):# Put the model in training mode model.train()# Initialize performance metrics running_loss =0.0 correct =0 total =0for batch_idx, (features, targets) inenumerate(dataloader):# Put the data and targets to the correct device features, targets = features.to(device), targets.to(device)# Reset the optimizer optimizer.zero_grad()# Make predictions predictions = model(features)# Calculate the loss loss = loss_fn(predictions, targets)# Calculate the adjustments loss.backward()# Update the model optimizer.step()# Track progress running_loss += loss.item() _, predicted = torch.max(predictions, 1) total += targets.size(0) correct += (predicted == targets).sum().item() average_loss = running_loss /len(dataloader) accuracy =100.* correct / totalreturn average_loss, accuracy
Now train the model for several epochs on the training data, and after each epoch get the validation loss and accuracy.